

官方文档 https://15445.courses.cs.cmu.edu/fall2021
PROJECT#3 QUERY EXECUTION
在这个 Task 中,我们需要在 bustub 中添加对查询执行的支持。通过添加不同的 execution 节点来支持不同的算子
Access Methods: Sequential Scan
Modifications: Insert, Update, Delete
Miscellaneous: Nested Loop Join, Hash Join, Aggregation, Limit, Distinct
这次的 Task 总体而言倒不会太难,只要搞懂火山模型的逻辑、理清各个算子背后的原理并且找得到对应的 api 调用(感觉这个倒是会比较花时间233)基本上就没啥问题了。坐下来大概零零散散花了三四天时间(其中还包括快做完的时候因为一次比较离谱的 git 操作导致直接 rollback 到了没做之前的状态,按着记忆又得重新敲一遍555)
先说一下执行计划总体的一个流程。查询执行的最顶层是一个ExecutionEngine,通过调用Execute函数执行查询,参数里面主要涉及到 AbstractPlanNode 和 ExecutorContext 两个主要的类。AbstractPlanNode主要定义了该次查询的计划,包括输出的列格式以及子查询计划节点,该抽象类会被具体的查询计划节点所继承,如SeqScanPlanNode并在子类中完善各自查询所需要的不同资源;ExecutorContext 涉及了事务相关的内容,包括事务类,锁管理,缓冲池管理等,详见下面的构造函数。
在执行查询计划时,首先应把 plannode 和 execcontext 定义完整
/**
* Creates an ExecutorContext for the transaction that is executing the query.
* @param transaction The transaction executing the query
* @param catalog The catalog that the executor uses
* @param bpm The buffer pool manager that the executor uses
* @param txn_mgr The transaction manager that the executor uses
* @param lock_mgr The lock manager that the executor uses
*/
ExecutorContext(Transaction *transaction, Catalog *catalog, BufferPoolManager *bpm, TransactionManager *txn_mgr,
LockManager *lock_mgr)
: transaction_(transaction), catalog_{catalog}, bpm_{bpm}, txn_mgr_(txn_mgr), lock_mgr_(lock_mgr) {}
/**
* Create a new AbstractPlanNode with the specified output schema and children.
* @param output_schema the schema for the output of this plan node
* @param children the children of this plan node
*/
AbstractPlanNode(const Schema *output_schema, std::vector<const AbstractPlanNode *> &&children)
: output_schema_(output_schema), children_(std::move(children)) {}
由于ExecutionEngine处于查询的顶层,因此在 Execute 执行时首先需要创建一个执行器
// Construct and executor for the plan
auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
接下来还需调用 executor->Init(); 完成执行节点的初始化,初始化的内容不一而足,但总体而言就是调用子查询节点的初始化以及迭代器初始化等
最后就是通过火山模型来调用下层算子来得到本层的结果,下面的代码就是很经典的火山模型,精髓就是这个Next()。
// Execute the query plan
try {
Tuple tuple;
RID rid;
while (executor->Next(&tuple, &rid)) {
if (result_set != nullptr) {
result_set->push_back(tuple);
}
}
} catch (Exception &e) {
// handle exceptions
}
简单来说,我们需要通过Next一次返回一个 Tuple,直到返回完所有的结果本层的 execute 才算执行完成,而不是调用一次Next就一次性返回所有结果。我在网上看到有人的实现是在Init里面就把下层所有的 Tuple 全部取出来存在容器里然后在 Next 中直接一个一个返回,我认为这并不是真正的火山模型,真正的火山模型应该是调用一次next 做一次相应的处理然后返回一个新值
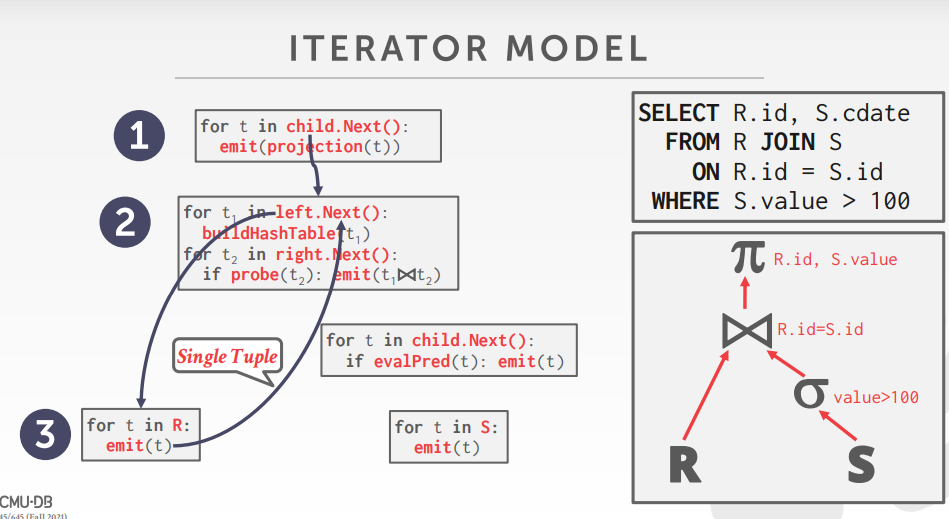
接下来就是各个算子相应的实现了
SEQUENCE SCAN
顺序扫描一张表,逻辑其实不算难,你需要一个 TableIterator 迭代器来遍历这个表
注意迭代器返回的 tuple 并不是我们需要的 tuple,需要通过 col.GetExpr->Evalute 由于我们可能并不需要所有的行,所以需要做一个筛选
const auto predicate = plan_->GetPredicate();
bool flag = predicate == nullptr || predicate->Evaluate(& tmp_tuple, GetOutputSchema()).GetAs<bool>();
如果这个 tuple 不符合我们的要求,不能简单地直接返回 false,不然上层算子就会以为这层算子已经结束遍历了,而是应该继续递归调用Next直到迭代器达到表尾
INSERT
我们需要支持两种不同的插入模式,一种是从 child_executor 获取 tuple 来做插入,另一种是直接插入 tuple。并且这两种插入不仅需要修改表本身数据,还要对索引进行相应的插入
if (plan_->IsRawInsert()) {
for (const auto &raw_value : plan_->RawValues()) {
Tuple insert_tuple(raw_value, &table_info_->schema_);
InsertTupleAndIndex(&insert_tuple);
}
return false;
}
// select from child_exec
Tuple insert_tuple;
RID insert_rid;
while (child_executor_->Next(&insert_tuple, &insert_rid)) {
InsertTupleAndIndex(&insert_tuple);
}
return false;
注意一次 Next 操作应该插入所有数据,然后一次性返回 false
UPDATE
Update 的逻辑也差不多,官方很贴心地提供了 GenerateUpdatedTuple 的接口,我们可以直接调用它得到更新后的 tuple
在更新索引的时候需要先删除旧索引再把新索引插入
DELETE
同上
NESTED LOOP JOIN
最朴素的 join 操作,就是做了一个内外表遍历联结。为了为u关于
HASH JOIN
AGGREGATION
理解它的逻辑比较难,不过只要理解了实现起来其实也就那样
在 Init 时就应该通过 InsertCombine 把所有 tuple 通过处理放到哈希表里,目的就是为了做一个聚类
while (child_->Next(&tuple, &rid)) {
// AggregateKey is the key that group by required
// AggregateValue is vector<Value>
aht_.InsertCombine(MakeAggregateKey(&tuple), MakeAggregateValue(&tuple));
}
同时哈希表里面维护了 Count,Min,Max,Sum 四种聚合运算种类,这部分运算官方都帮我们实现好了并且封装在 InsertCombine 里了
在 Next 里面通过迭代器来遍历建完的哈希表,我们的实现需要考虑 Having 的情况,因此还需要加一个判断
// make use of the HAVING clause for constraints
const auto having = plan_->GetHaving();
bool flag = having == nullptr || having->EvaluateAggregate(agg_key.group_bys_, agg_val.aggregates_).GetAs<bool>();
if (!flag) {
return Next(tuple, rid);
}
LIMIT
没啥好说的,维护一个计数器就完了
DISTINCT
和 Aggregation 类似,同样用到哈希表方法,需要新建一个 HashDistinctKey 结构体并且重写 == 运算符和 hash 方法
对于输出的每一个列都需要判断重复性
放成绩
好卷好卷,懒得再优化了,早点做完才是王道
值得一提的是 GradeScope 的 GTEST 版本的代码风格不满足 clang-tidy 要求的代码风格,导致如果按要求提交源代码上去会直接爆零

解决方式也非常傻_,只要在提交的时候多打包一个文件

陆陆续续有同学在 issue 上面报告了这个问题,Pavlo 从三月开始就说要修复,结果到现在还没修好,我寻思应该就是修改个版本的事情,应该不至于拖这么久吧,属实是鸽子行为了捏hhh




