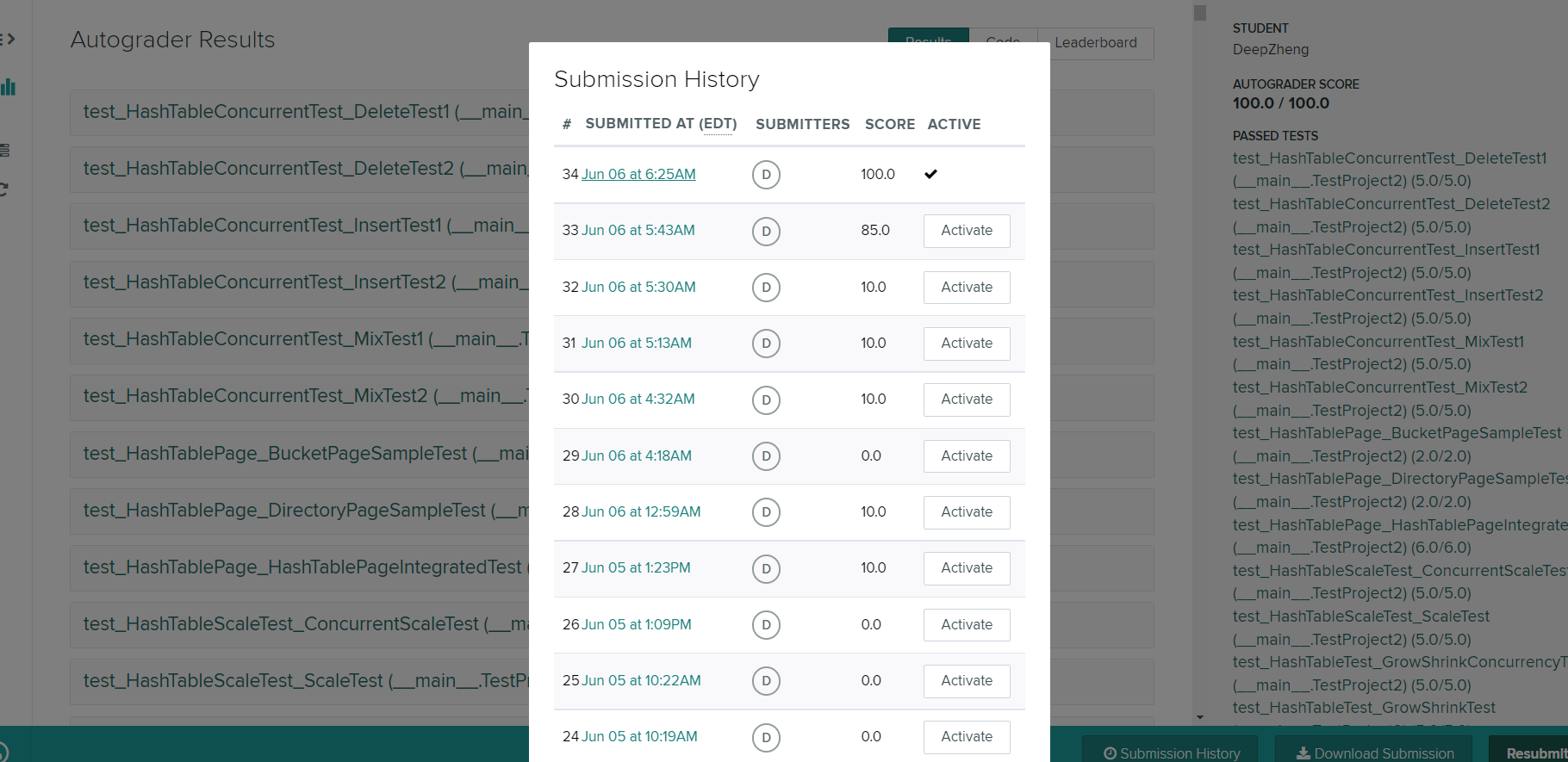
官方文档 https://15445.courses.cs.cmu.edu/fall2021
PROJECT#2 EXTENDIBLE HASH INDEX
如果说 Project 1 不看课还可以尚且一做的话,Project 2 不看课就是真的做不下去了。起码仅凭实验要求里的那么一小段说明我是不知道这个 extendible hash 讲的是什么
简要来说,我们这里采用的 hash 方式为链式哈希,使用 bucket (桶)这么个东西来存储 page;不同于常规的 chained hashing 那样 hash(key) 不变,指向的 buckets 桶链表可以往下延伸(最坏情况下又会退化成O(n)的遍历)
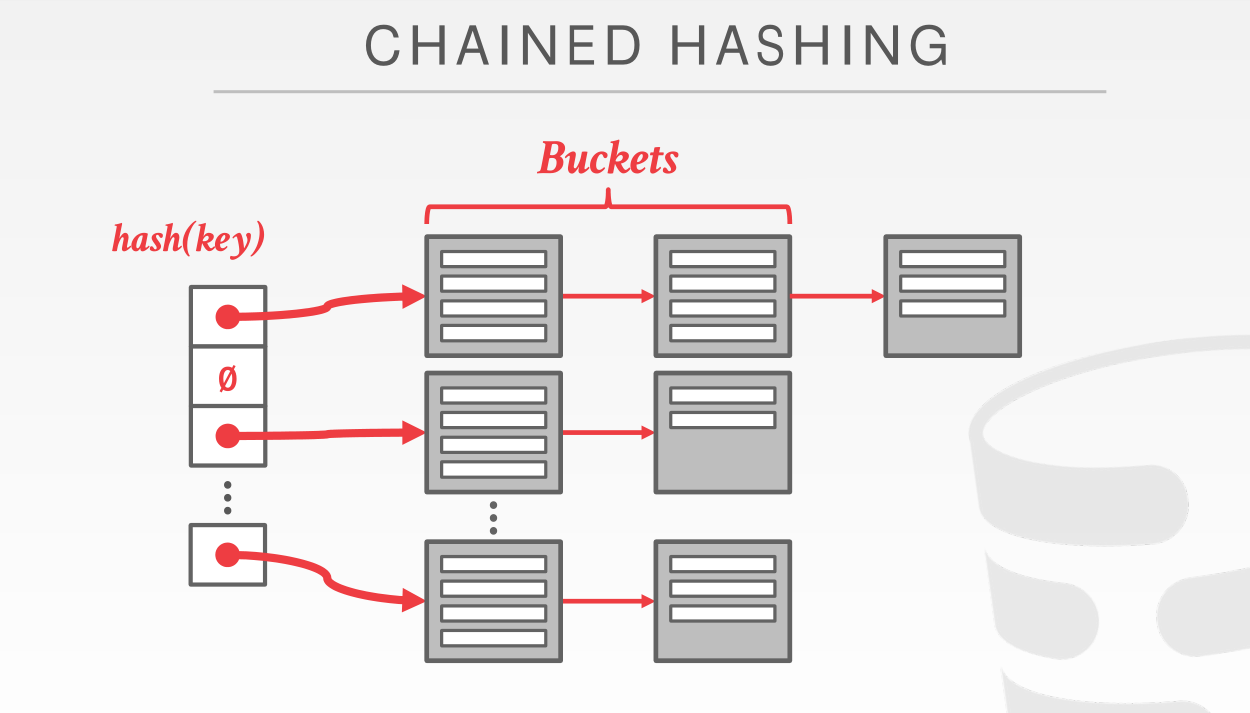
这里的 extendible 可扩展性具体指的是通过 mask 这个算子来完成对不同 bucket 的映射(计算方式与子网掩码相同)
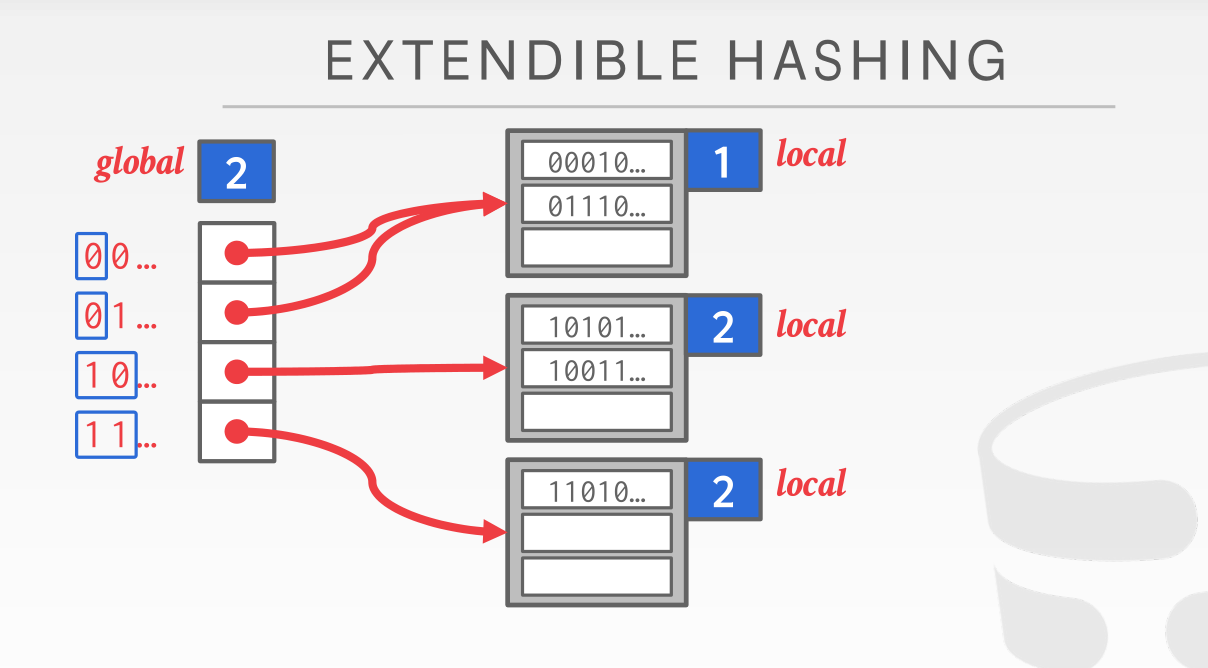
我们维护一个全局的 global_mask 以及每个桶都有自己的 local_mask,对于一个到来的 hash 值,我们首先用 global_mask计算出这个 key 应该被归到哪个桶(注意多个 slot 可以指向同一个 bucket)
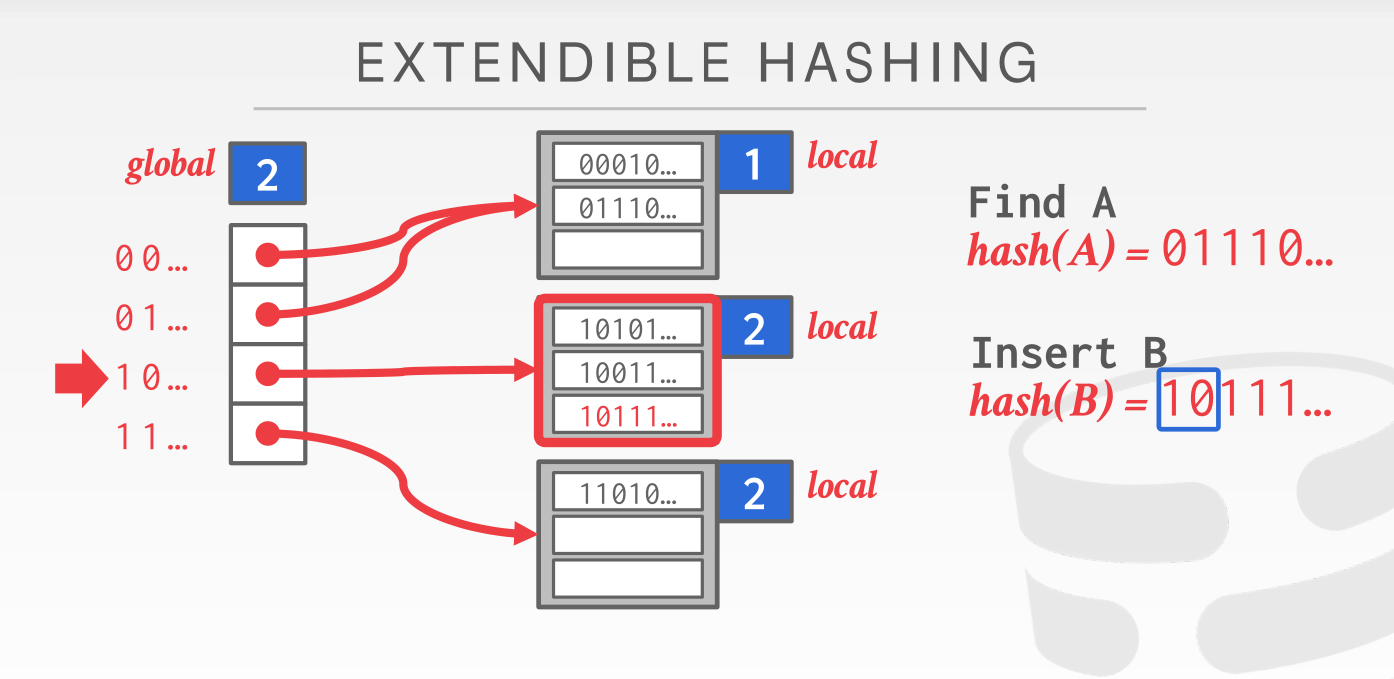
那么当某个 bucket 填充满的时候又会发生什么情况呢?
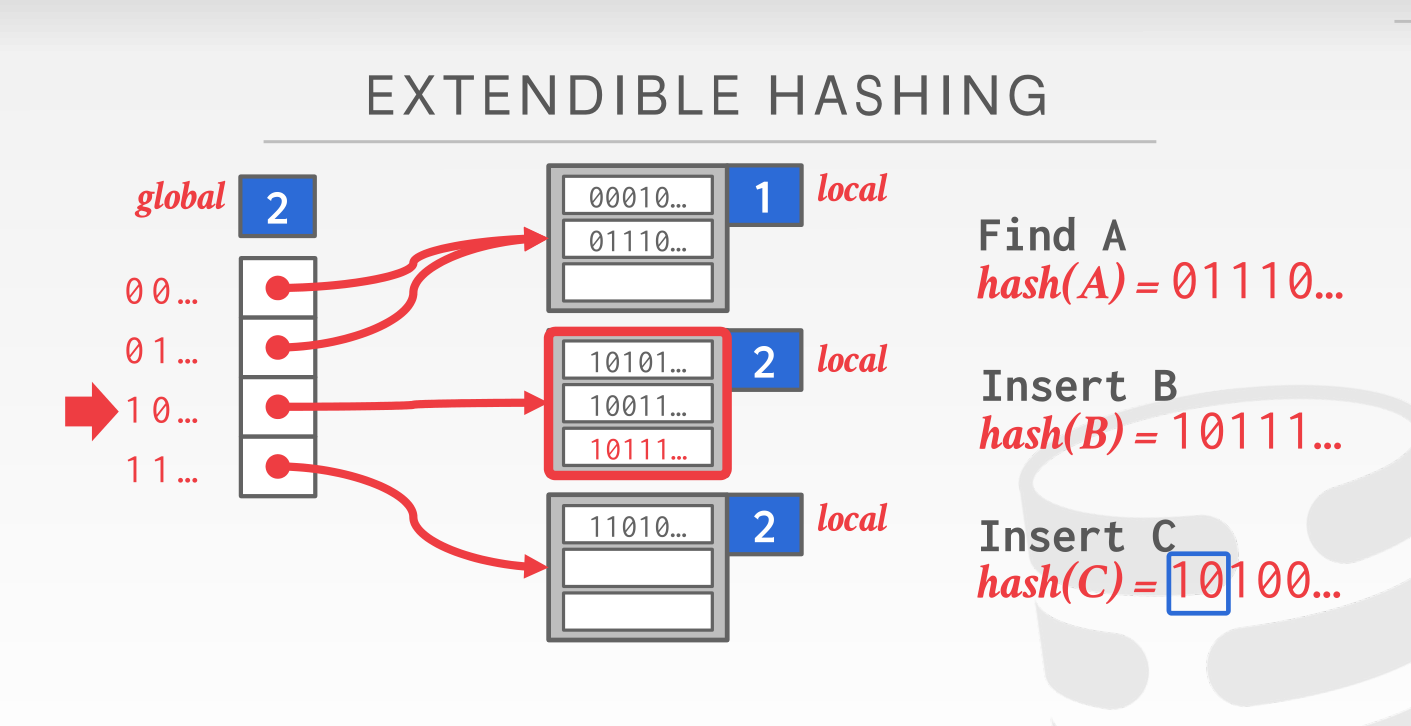
这个时候就需要做拆分了。由于‘10’标志位无法容纳下那么多的 key,所以我们需要把这个超限的桶拆分成两个,并且把local_mask标志位都加 1(global_mask维护的是所有桶 mask 标志位的最大值所以也需要同步加 1)。在 global slot 完成重定向,以及两桶的数据拆分
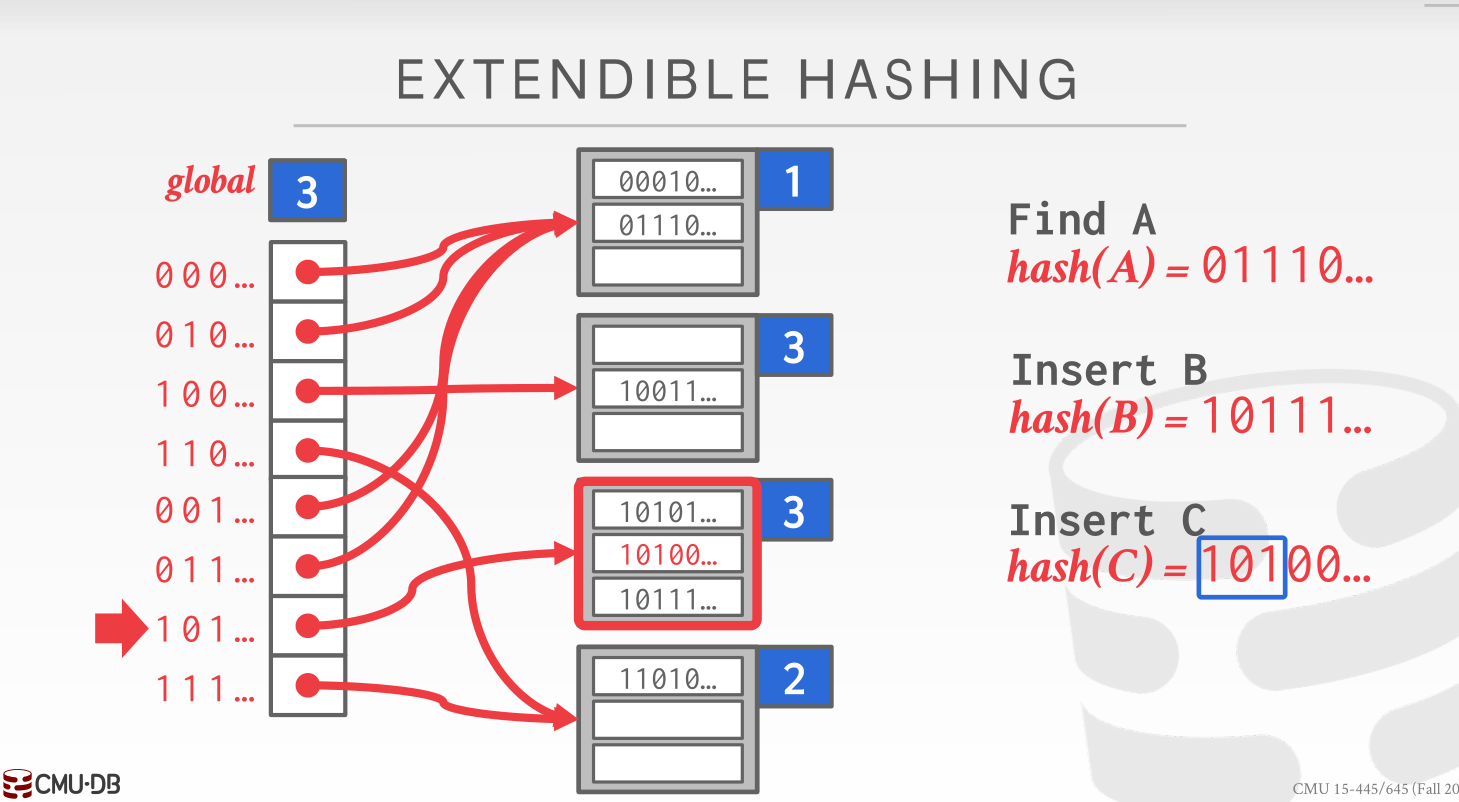
此时就能正常完成插入了
注意在实验里面对于 key 的掩码处理其实是从后面的位开始算的(LSB),和图上的是反过来的,这样的话提出的值可以直接当成数组下标来用
TASK #1 PAGE LAYOUTS
如果想要我们的哈希表做到数据持久化,即断电后数据还能重新恢复,那哈希表的元数据就必须同样也要存储在磁盘中。这个 Task 需要我们完成两个文件
- Hash_table_dirctory_page
- Hash_table_bucket_page
来支持对于 hash table buckets 的文件读写
HASH TABLE DIRECTORY PAGE
这个页面管理的是 hash table 的元数据,包含

有几个函数是比较需要注意的
-
uint32_t GetSplitImageIndex(uint32_t *bucket_idx*)一开始没看明白这个函数是用来干什么的,但是做到后面桶的分裂和合并的时候就很需要它了。简而言之它的作用就是用来获取当前 bucket 根据当前深度(注意这时候的深度应该是分裂增加或者合并缩减之前的深度)对应的 bucket,这个 split_image_bucket 用来存分裂后原 bucket 拆分的键值对以及合并后原 bucket 也要并入到这个 split_image_bucket 里面去
实现方式也很简单,就是把传入的 bucket_idx 对应 local_depth 的那一位取反就行了
比如说 0000 1001,深度为 3,那么它的 split_image_index 就是 0000 1101
-
bool CanShrink()判断是否可以缩容;即当所有桶的 local_depth 都比全局 global_depth 小的时候,认为当前桶量出现冗余,可以进行缩容
-
void IncrGlobalDepth()增加全局 global_depth,但是全局深度增加后全局的 depth 数组和 page_id 数组大小也翻了一倍需要进行初始化(其实就是把原来的复制一遍),所以我写了一个
Grow()函数来干这个事情
然后其他的就没有什么问题了,这里不需要担心锁的问题()
HASH TABLE BUCKET PAGE
这里就需要实现对应的桶页逻辑
类里面维护了三个数组成员
- occupied_ :用于判断该 bucket 该位置是否被访问过
- readable_:用于判断该 bucket 该位置此时是否存有数据
- array_:用于存储真正的键值对
// For more on BUCKET_ARRAY_SIZE see storage/page/hash_table_page_defs.h
char occupied_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1];
// 0 if tombstone/brand new (never occupied), 1 otherwise.
char readable_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1];
// Do not add any members below array_, as they will overlap.
MappingType array_[0];
其中 occupied_ 在这里的意义我感觉不太大的样子,除了方便判定是否需要继续遍历数组(某个 occupied_ 为 0 没有访问过的话说明在它之后的都没有被访问过)
array_ 是零长数组,解释参见(https://blog.csdn.net/gatieme/article/details/64131322)初始化的时候在内存里是不占空间的,但是它真正能使用到的空间就是固定的 page 大小减去前面成员变量之后所剩的空间。因为实际上 BUCKET_ARRAY_SIZE 是固定的,为了不使内存溢出,注释也强调了不要在下面再加别的成员了(所以挺困惑我的一点就是既然总的 page 空间大小和数组 size 都定下来了,为什么不直接在初始化的时候就申请那么大的空间呢)
更新: 现在我大概理解了。虽然bucket_page 大小是固定的,但是由于 MappingType (std::pair)的类型并不固定,所以大小不一致,这就使得 array_ 的大小不好分配,声明为零长数组的话就可以灵活使用了,算是一个小 trick 吧
这里需要实现的成员函数都还算简单,涉及到比较多的位运算,要仔细一点算好 index 和 offset 以及是置 0 还是置 1,还有是对位进行操作还是对整个字符(也就是 8 位)进行操作
TASK # 2 &3 ExtendibleHashTable & CONCURRENCY CONTROL
这里我把任务 2 和任务 3 放在一起了,反正任务 3 就是任务 2 实现的内容进行一个并发的控制,其实也是顺手加个锁的事情(虽然锁的粒度对最后性能影响还是挺大的)
这个部分我们要做的就是把之前实现的 bucket 和 directory 整合到一起,加上复杂的逻辑,实现Insert,GetValue,Remove
听起来虽然很简单,但是实际上里面的逻辑个人感觉是非常复杂的,尤其是对于 Insert 时候桶满分裂的处理和 Remove 之后桶空合并的处理是需要非常细致的
其他的函数略去不表,重点讲讲 Split和 Merge的操作
拆分页面需要的步骤
- 加表级写锁
- 获取目录和当前 bucket 的数据
- 判断 directory 里面 global_depth 是否需要增加(local depth == global depth),此时除了增加全局深度,其他的数组也要扩容,参见上面的
Grow()。然后当前 bucket 的 depth 也要自增 - 新建一个 bucket,index 就是上面的 splitimageindex,深度什么的和原来的桶一致
- 遍历一遍原来的 bucket,获取原 bucket 的所有 kv pair ,然后再把原 bucket 重置一遍
- 最后把 copy 到的所有 kv pair 重新算一遍 index 决定要放到哪个 bucket 里面
其实在最后 kv pair 重新组合的时候,我原本采用的操作是直接对原 bucket 进行操作,应该拆分的先 remove 然后 insert 到 image bucket 里面,但是这样线上测试会报内存问题直接零蛋。。很难理解为啥会这样,有空的时候再查查吧
而合并页面的逻辑就会比较清晰一点
- 加表级写锁
- 获取目录和当前 bucket 的数据
- 判断当前 bucket 的深度,如果为 0 就不进行收缩
- 如果当前 bucket 与其 split image bucket 深度不同,说明两个中的一个已经进行拆分了,这时候也不收缩
- 给当前 bucket page 加上读锁,再判断一次是否非空(考虑到并发是有可能存在乱入的情况的),这时候也不收缩
- 这时候才能认为 bucket 已空,真正进行删除操作
- 接着设置原 bucket 的 page为 split image 的 page,即合并 target 和 split
- 最后遍历整个 directory,将所有指向原 bucket page 的 bucket 全部重新指向 split image bucket
- 通过之前实现的
CanShrink判断是否可以收缩 global depth
当然,对于遍历 directory 还是有优化的方式的
size_t index_diff = 1 << local_depth;
// change bucket_page_id 指向
for (size_t i = target_bucket_index - index_diff; i >= 0 && i < target_bucket_index; i -= index_diff) {
dir_page->SetBucketPageId(i, image_bucket_page_id);
dir_page->SetLocalDepth(i, dir_page->GetLocalDepth(target_bucket_index));
}
for (size_t i = target_bucket_index + index_diff; i <= dir_page->Size(); i += index_diff) {
dir_page->SetBucketPageId(i, image_bucket_page_id);
dir_page->SetLocalDepth(i, dir_page->GetLocalDepth(target_bucket_index));
}
通过观察就可以发现,每个 image_index 之间刚好隔着 2^local_depth^的距离,所以只需要遍历这些 index 就好了
还有一个很重要的点就是每次使用完一个页面之后记得及时 Unpin,在这上面吃了好多次大亏
顺便说一句,官方给的本地测试实在太弱了
过了 SampleTest 兴高采烈提交到 GradeScope 就会发现是个大零蛋
需要测试的话还是得靠自己手写 test
或者还用一个非常直球的方法偷官方的 test case((
std::ifstream file("/autograder/bustub/test/container/grading_hash_table_scale_test.cpp");
std::string str;
while (file.good()) {
std::getline(file, str);
std::cout << str << std::endl;
}
不管怎么说,满分万岁((
真的累死我了写这个 project,写这篇文章也一样((