

论文全称
HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements
Introduction
众所周知,数据库系统的性能对超参数的特定配置非常敏感。然而,由于数据库和调优的复杂性,这样的任务几十年来都是由数据库管理员(DBA)手动完成的。由于人工调参费时费力成本过高,所以使用自动调优策略来调整参数的研究一直在进行中。现有的工作主要分为两大类:基于搜索的方法和基于学习的方法。基于搜索的方法使用启发式策略在由旋钮候选值构建的搜索空间中探索理想的构型。例如,Best-Config 使用一组启发式规则手动构建搜索策略。为了在大搜索空间中提高调整性能,在节点可以连续取值或节点数量较多的情况下,基于学习的方法通过学习历史行为和经验样本来改进探索。例如,iTune 和 OtterTune 将搜索空间建模为高斯过程,并应用机器学习分类器和排序来缩小搜索空间的范围,同时使用贝叶斯优化来自动构建搜索策略。另一类方法使用强化学习模型来扩展搜索空间,例如 CDBTune 通过 DDPG 对状态(数据库实例评估矩阵)和动作空间(参数旋钮)进行建模并获得端到端的策略
HUNTER 承接 CDBTune,在 CDBTune 的缺陷上做出了算是相当大的改进,从下面的架构图也可以看出来,在架构上的设计更复杂也更精妙
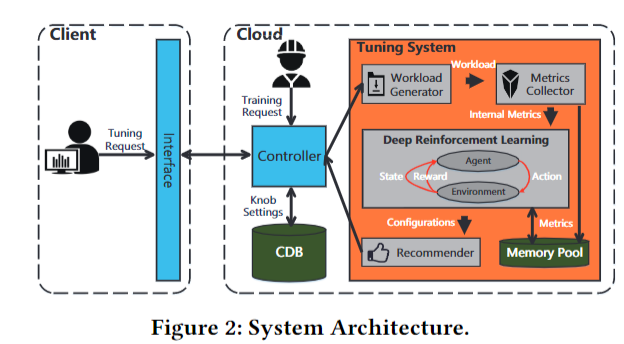
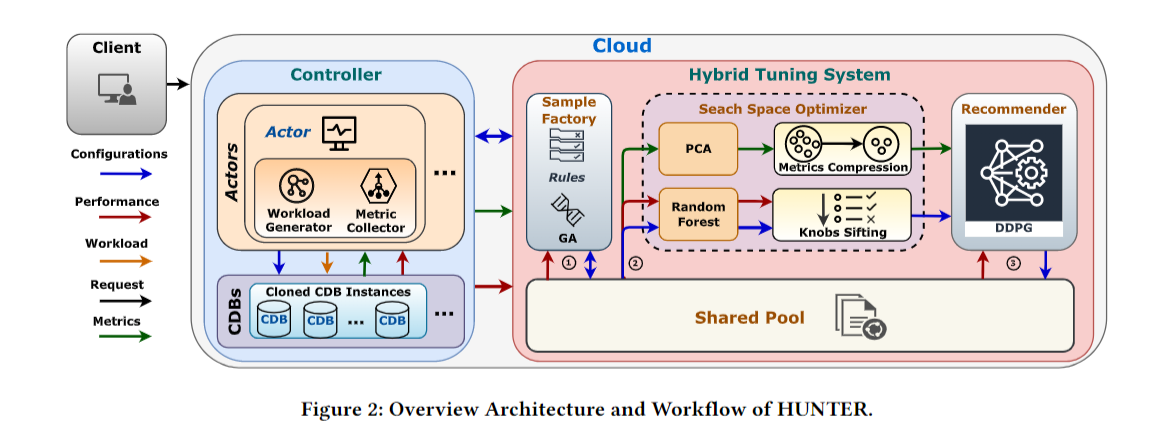
首先说说 CDBTune 在设计上的缺陷
-
可用性:
CDBTune 在调优期间是无法使用的,同时对于某些参数的调整还需要重启数据库
-
数据集多样性
用户负载和需求是具有多样性的。从预训练的模型迁移到具体实例上进行调优任务效果不太理想
-
冷启动
CDBTune 对于热启动调优过程的支持仍然不太好。对于冷启动而言,需要初始化生成负载进行训练,这使得调优时间大大增加
-
并行化
由于冷启动问题,工作负载生成与执行占用了大量的时间。同时,强化学习的使用本身对并行化就不是很友好
因此,本文的 HUNTER 就着重优化了这些问题。HUNTER 的一个突出特点是:它结合了两个学习模型:(1)元启发式算法模型和 (2)深度强化学习(DRL)模型。HUNTER 不依赖于预先训练的模型来热启动DRL(如DDPG),而是使用遗传算法(GA)来生成DRL样本,并通过主成分分析(PCA)和随机森林(RF)来减少搜索空间。此外,我们还提出了一种快速搜索策略(FES)来优化DDPG的搜索策略,从而提高了推荐速度
对于并行化和可用性的问题,HUNTER 采用了克隆 CDB 来解决。通过克隆多个 CDB 实例并在克隆 CDB 上执行训练和调优,调优结束后再把最优配置复制到主实例上。在这段过程中,主实例依然可以正常工作
系统结构
Controller
Controller 负责与执行模块 Actors 和 CDB集群 组成,Actors 由多个 Actor 组成,每个 Actor 负责与一个克隆 CDB 实例进行交互,交互内容包括通过 Workload Generate 克隆 CDB 上的用户实例,通过Metric Collector从 DBMS 收集运行信息,以及管理克隆 CDB 上的并行执行。
Hybrid Tuning System
该模块为调优系统的核心模块,相比于 CDBTune 做出了非常大的优化。
Sample Factory
由于用户需求的多样性,需要对某些配置做出更改的约束,在这里我们用 Rules 来表示。对于预训练模型,由于缺乏 Rules 的约束,很难输出令人满意的配置,所以在 HUNTER 中,抛弃了离线训练的模式,通过在线训练输出更 fit 的结果
有了 Rules 的约束,我们还需要生成初始负载样本(样本即为 configuration )。冷启动对于初始样本的质量很 sensitive,因为通过 try-and-error 选择样本。而冷启动一开始时对环境是未知的,生成的初始样本就是我们所知的初始训练环境了。所以我们输出的最优解也会落在这个初始的样本集中。如果我们采样到的样本集质量不够高,很可能得到的 local optimal 就会和 global optimal 相差甚大
为了得到高质量的初始样本,HUTER 采用 GA 遗传算法来探索生成样本。GA 不需要任何先验样本,因此可以在较少样本的情况下调整数据库配置;并且 GA 可以充分利用高性能参数之间的相似性,通过交叉和变异快速学习。
注意 GA 只是在粗粒度上探索了搜索空间,只是为了快速探索出较优的配置,为后面热启动 DRL 的细粒度调参降低搜索压力
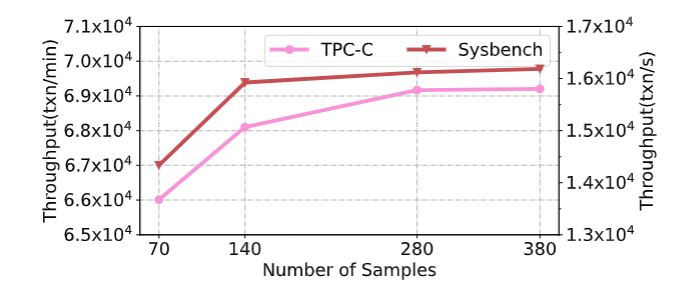
为了获得合理数量的生成样本,使用 GA 获得不同数量的样本,通过 65 个 knob 执行 10个小时的 DRL。性能变化如下,可以看到,性能随着样本数的增加而提高,但在 140 之后变化不大,因此选用 140 作为 GA 生成样本数量
GA 算法流程待补
Search Space Optimizer
DDPG 训练速度不但受到样本质量的影响,还受到数据维度的影响。如果把 所有 knob 全部丢进去网络里面训练,训练时间很高不说,里面可能存在一些对性能无关紧要的 knob。HUNTER 采用和 OtterTune 相同的思路,在训练之前又加进去一个搜索空间优化器,通过 PCA 和 RF 把动作空间压缩到一个合理的维度
-
PCA
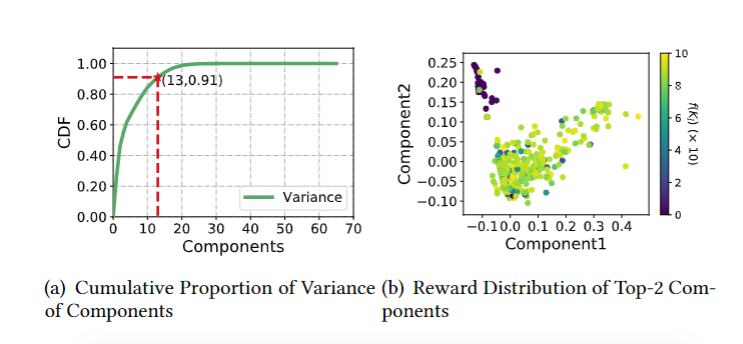
在 HUNTER 中,PCA 将数据\(X \in \mathbb{R}^{u\times l}\) 转换为低维数据 \(Z \in\mathbb{R}^{v\times l}\),其中 u 为原始状态指标维度,l 为原始状态指标的个数,我们的目的就是把 u 维 knob 压缩到 v 维
定义一个压缩矩阵 \(P \in \mathbb{R}^{v\times u}\),此时 \(Z = PX\)
通过实验,当 v = 13 时在速度和性能之间取得一个平衡
-
Random Forest
随机森林是由多个决策树组成的投票算法,用于计算特征的重要性,在 HUNTER 中,决策树采用 200 棵 CART 树。输入为 configuration 的子集,标签是它们对应的性能。
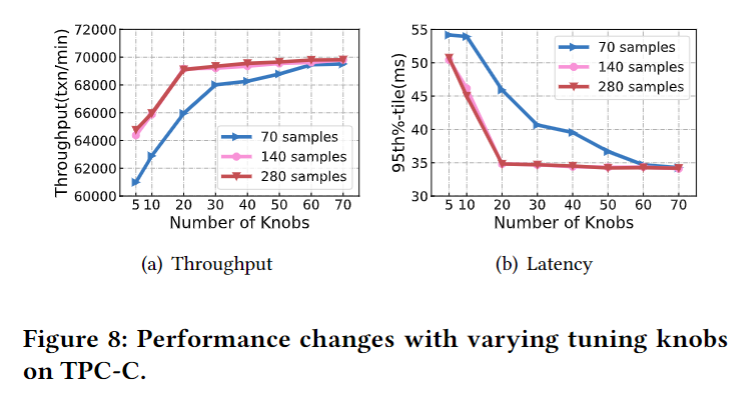
最终在 Sample Factory 生成的 140 个样本中选择与性能关系最大的前 20 个 knob
Recommender
Recommender 采用 DDPG 算法,便于处理连续动作值。State 输入为经过 PCA 降维的指标,Action 输入为经过 RF 选择后的 top-20 knobs,Environment 即为克隆 CDB 实例,在 HUNTER 中, 通过 Controller 来管理多个 CDB,使得算法与环境解耦
为了更快提高收敛速度,HUNTER 在原生 DDPG 上将原来的探索策略优化为快速探索策略 FES

当 \(t = 0, P(A_c)=0.3\),这一改进能使模型在调优的初步阶段有更大的可能选择性能最好的配置,并迫使模型基于相对更好的配置进行探索
有些不太理解的 point
- 在 Sample Factory 里面,对于初始化要求高质量样本的问题,论文说样本被期望近似到指向最优配置的路径,如果最优解不在当前的采样中,很难 capture 到最优的配置。我的理解是初始样本好坏只是关系到初始的性能表现,有些原始的 DDPG 生成的样本甚至只是随机采样出来的,只要动作空间是固定的,环境是固定的,初始配置好一点应该只是会加快收敛速度【?
- 关于工作负载漂移(Workload Drift)的问题,论文里没有详细解释,也搜不到什么相关的资料,不是很了解,可能意思是在短时间内 workload 发生了比较大的变化?
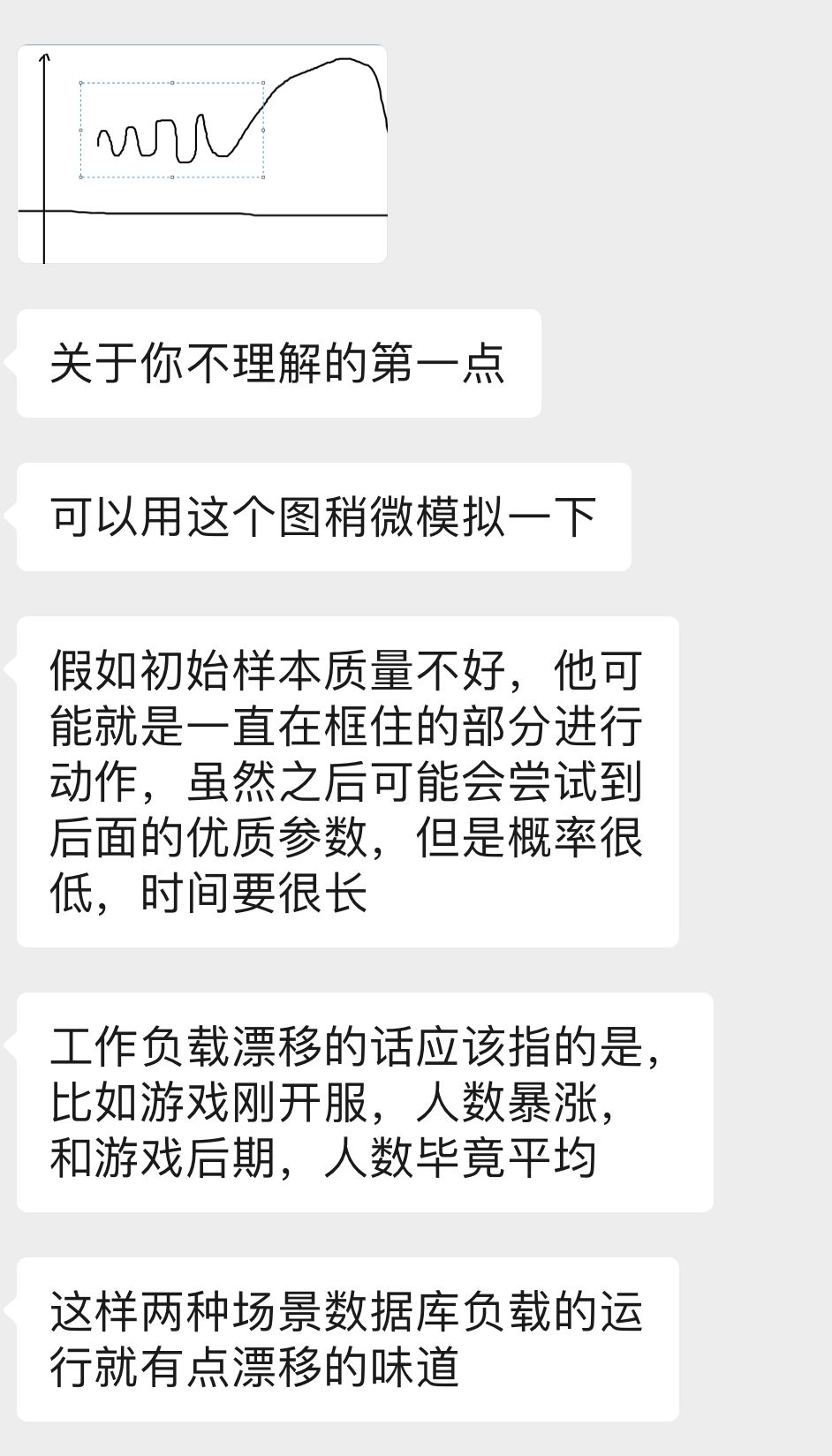
感谢彭同学的答疑解惑




