

本文基于 MySQL8.0 Innodb
查找过程
首先我们创建这样一个表
CREATE TABLE info(
id int(10) AUTO_INCREMENT,
name VARCHAR(100),
age TINYINT(4),
PRIMARY KEY (id),
INDEX IDX_AGE (age)
)ENGINE = innodb CHARSET=UTF8;
自增的 id 作为主键,name 和 age 创建了一个联合索引
然后我们插入下面的数据
INSERT INTO info (name, age) VALUES ('刘洪',29);
INSERT INTO info (name, age) VALUES ('王五', 32);
INSERT INTO info (name, age) VALUES ('张三',12);
INSERT INTO info (name, age) VALUES ('刘九',46);
INSERT INTO info (name, age) VALUES ('郑七',46);
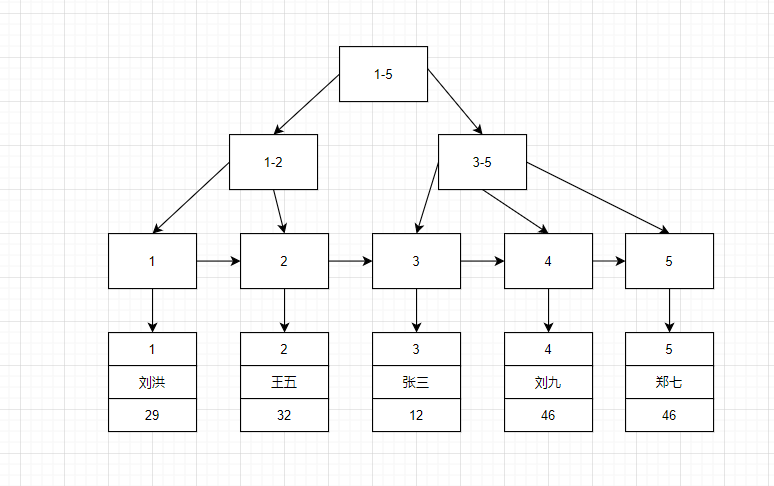
此时,id 作为主键,默认是聚簇索引,其叶结点存的是整行的数据
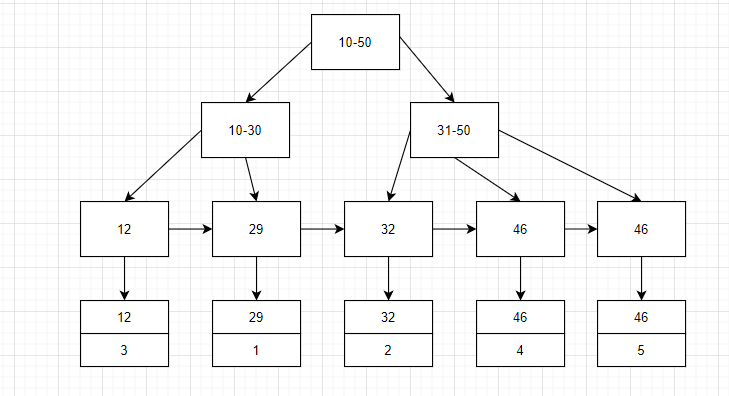
而 age 作为普通索引,非聚簇索引,其叶结点存的是聚簇索引的指针
查询
- 如果查询条件为主键(聚簇索引),则只需扫描一次 b+ 树即可通过聚簇索引定位到要查找的行记录数据。
如 SELECT * FROM info WHERE id = 1
- 如果查询条件为普通索引(非聚簇索引),那么需要扫描两次 b+ 树,第一次通过扫描普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据
如 SELECT * FROM info WHERE age = 12
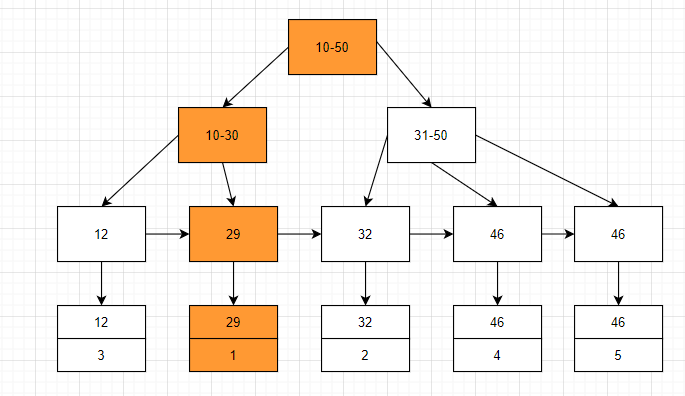
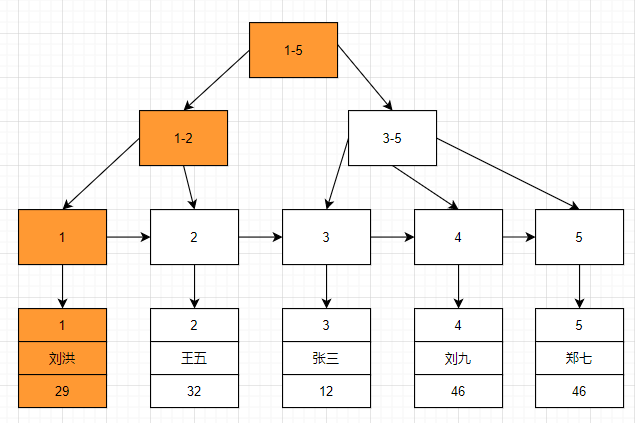
这样的查询流程就叫做回表查询
回表查询需要扫描两次索引树,因此性能上会比较低一些
所以我们可以通过索引覆盖来提高查询性能
索引覆盖
那么什么叫索引覆盖呢?
顾名思义,我们创建的索引覆盖了要查询的字段,因此只需要扫描一次索引树就可以取到我们要的结果。
就像这样 SELECT age, id FROM info WHERE age = 46;
age 索引树叶结点中存储了 age 和 id 的值,而我们只需要 age 和 id 的值,因此只需要通过一次查询就可以得到结果,无需回表,速度更快
如果我们考虑这样的查询
SELCT age, name ,id FROM info WHERE age = 46;
在前面加个 EXPLAIN 分析一下

可以看到,Extra 列是NULL,说明进行了回表查询。因为 age 索引树上只存了 age 和 id 的值,要找到 name,只能回到聚簇索引树上再进行一次查询
怎么优化才能只需要查一次表呢?答案是建立一个联合索引
联合索引
我们建立一个索引组合
DROP INDEX IDX_AGE ON info;
CREATE INDEX IDX_AGE_NAME ON info(age,name);
再进行一次查询

可以看到,这次建立了联合索引之后,age、name、id 的值都在一个索引树上,实现了索引覆盖,此时就不需要回表查询了。因此 Extra 列显示的是 Using Index
联合索引树结构
单索引的树很好想象,那么对于联合索引,它的树又长什么样子呢?我上网一查,发现能把结构讲清楚的文章很少,这些文章里面,又有很多都是复制的同一篇。。。这篇文章介绍的结构大概是这样的
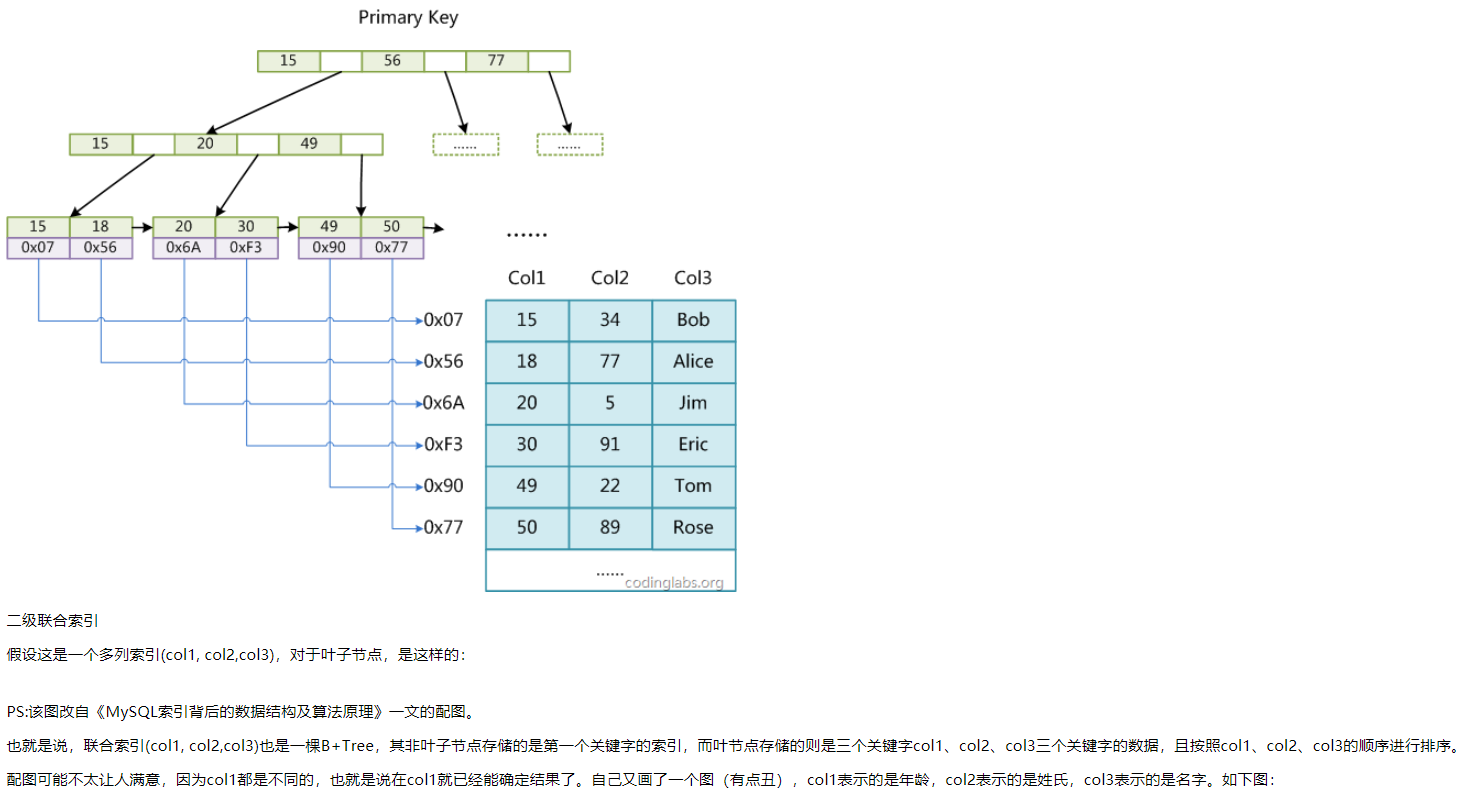
它的大致意思就是,联合索引在 b+ 树的非叶子节点中只会存储联合索引中的第一个索引字段的值,叶结点才会存整个联合索引的数据,并且按照索引的顺序进行排序
但是直觉告诉我,这样的结构是不对的。我的理解是既然建立联合索引了,那索引里的所有字段应该都是合在一起来建树的,否则按上图的方式岂不是相当于建了一个微型的聚簇索引,那不还是相当于单索引么。
然后我又搜到了另一篇文章,这个应该才是正解。
借用一下他的图
假设我们有这样一个表
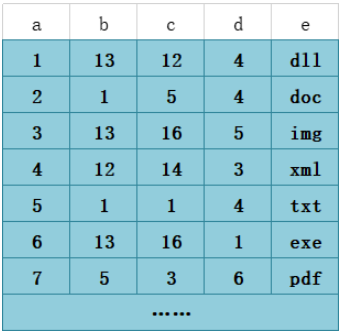
其中 a 是自增的主键,我们对(b, c, d)建立一个联合索引
那么这个联合索引在 b+ 树上的结构就是这样的
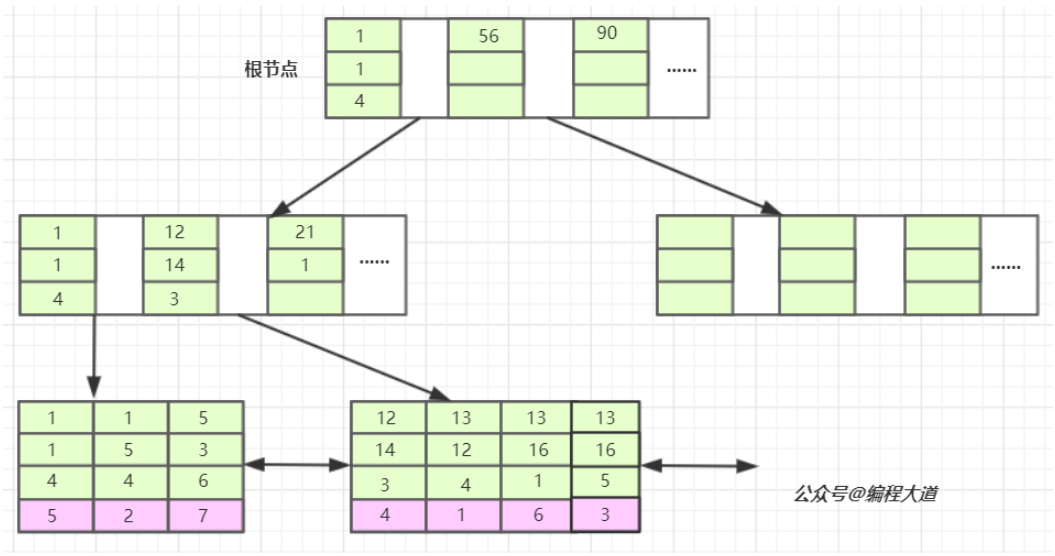
和我想的一样,对于非叶子节点,同样也会存整个联合索引的键值;又因为这个联合索引本质上还是个非聚簇索引,因此在叶子节点里的 data 部分还会存一个联合索引所在行的主键值(上图紫色部分)
联合索引的最左匹配原则
对于联合索引来说,相比于单列索引,它的单节点中是多列的,因此需要按照顺序来进行匹配。
假设我们有这样一条查询语句
SELECT * fROM T WHERE b = 1 AND c = 5 AND d = 4;
-
存储引擎首先从根节点开始查找,并根据第一个索引字段进行匹配,1<=1<56,因此从这两个索引中间读到下一个节点的磁盘页
-
将这一页加载进内存中后,又进行一次判断,1<= 1 < 12,继续通过指针加载下一个磁盘页
-
此时处于叶子节点中,存储引擎按索引顺序进行逐个匹配,最终获取到目标行,并根据索引值关联的主键进行回表查询
通过上面的流程和图,不难发现,对于叶结点的链表,第一列(索引 b 列)从左到右是递增的。而第二列是在第一列相等的范围内实现的递增,第三列则是在第二列相等的范围内实现的递增。
换句话说,我们创建的(b,c,d)的联合索引,其实就是相当于创建了(b),(b,c),(b,c,d)三个索引。任何查找条件不按索引顺序来的,都没办法用到这个索引
这样的结构其实就和电话本(或者任何查找联系人的东东)很类似,联合索引就相当于姓名,电话本里的排列顺序是不是就是先按姓(首字母排序)来排,然后依次名的第二个字,第三个字。你要查找一个联系人的时候,是不是也是按照先姓后名的顺序来找的呢?如果你只知道名字不知道姓,比如说张秋菊你只知道秋菊或者一个菊,那查找起来就比较困难了。
联合索引的范围查询
由于联合索引树的结构,导致对于联合索引的查询必须严格遵守最左匹配原则,如(a,b,c)的联合索引,满足的查询顺序只能是(a)(a,b)(a,b,c)。那么对于范围查询呢?
考虑下面的查询语句
SELECT a,b,c FROM t WHERE a = 1 AND b > 20 AND c = 10;
首先,a 作为第一列,肯定用到了索引;而 b 是在 a 列值相等情况下实现的有序,因此也可以用到索引;而 c 列就不行了,因为它之前的 b 列并不是固定的,所以在经过 a 和 b 筛选出的范围内 c 并不是有序的,因此也就无法使用索引来查询了
但是,神奇的事情发生了。当我用 EXPLAIN 查询上面的语句的时候,发现并没有出现回表查询的情况,c 列仍然正常用到了索引
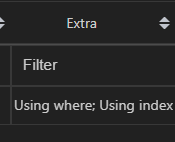
这是为什么呢?我上网查了一下,发现 MySQL 从 5.6 之后就用了个叫索引下推的东西,所以使得在范围查询之后还可以继续使用索引。真是神奇,有空可以好好研究一下这个索引下推

查询速度比较
回到上面的回表查询,考虑下面的查询语句
SELECT * FROM info WHERE age = 46 AND name = '郑七';
SELECT age, name ,id FROM info WHERE age = 46 AND name = '郑七';
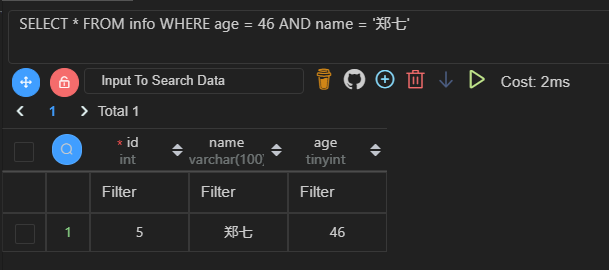
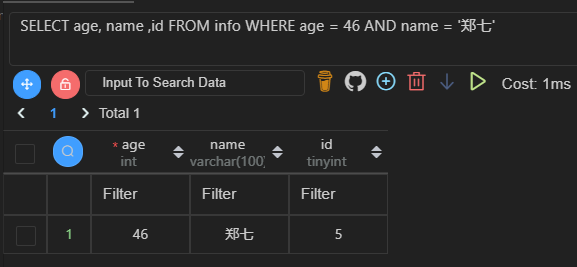
需要回表查询的语句耗时是只要单次查询的两倍,我的表还是只有 5 条数据的小表,如果是千万级别的大表,那差距就很大了。




