本文为斯坦福大学计算机网络课程 CS144 编程任务 Lab Assignment 1 的学习小结
官网 https://cs144.github.io/
Lab 1 文档 https://cs144.github.io/assignments/lab1.pdf
个人实验备份代码 https://github.com/deepzheng/sponge
Putting substrings in sequence
在该 Lab 中,我们将被要求实现一个流重组类,可以将 Sender 发来的带索引序号的字节碎片重组成有序的字节流供 socket 读取
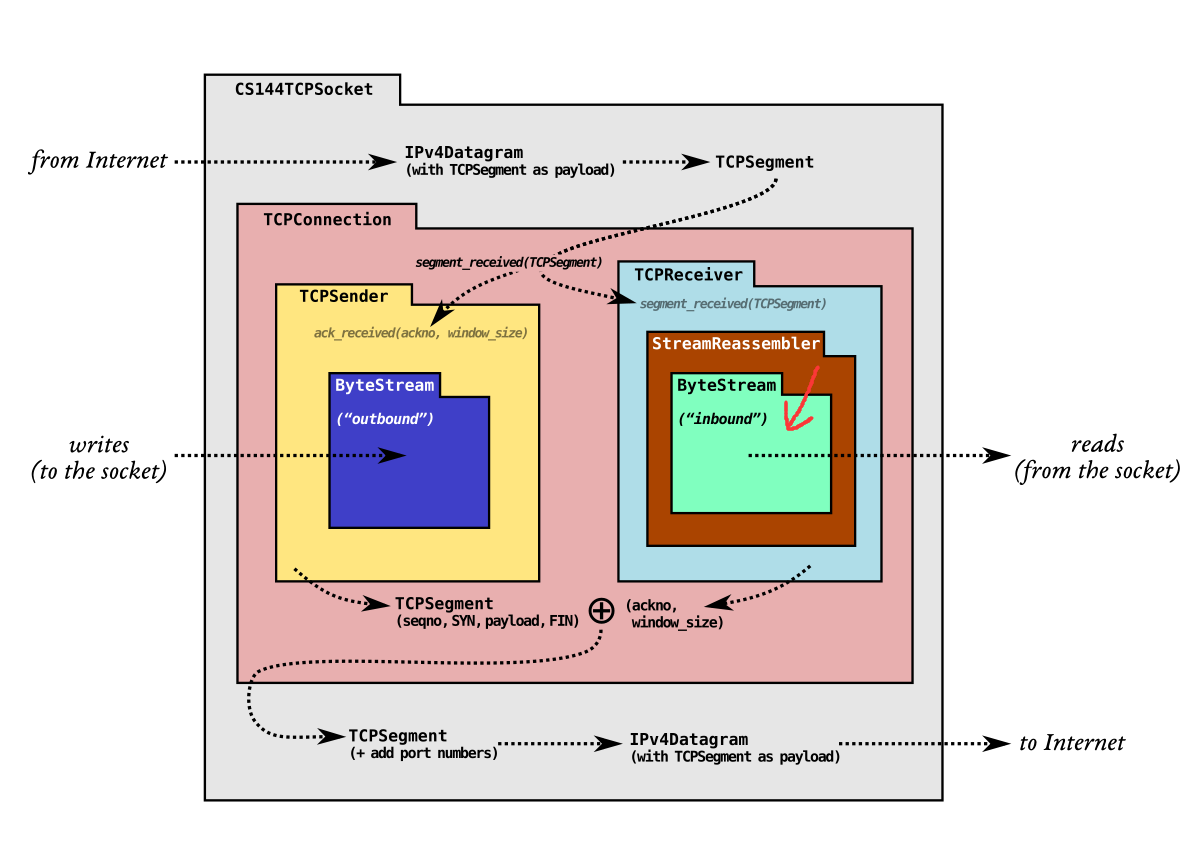 上图为官方提供的在这次课程中我们要构建的整体框架,在 Lab1 中我们需要实现 StreamReassembler 类来将字节碎片重组成有序字节流并传递给在 Lab0 中实现的ByteStream
上图为官方提供的在这次课程中我们要构建的整体框架,在 Lab1 中我们需要实现 StreamReassembler 类来将字节碎片重组成有序字节流并传递给在 Lab0 中实现的ByteStream
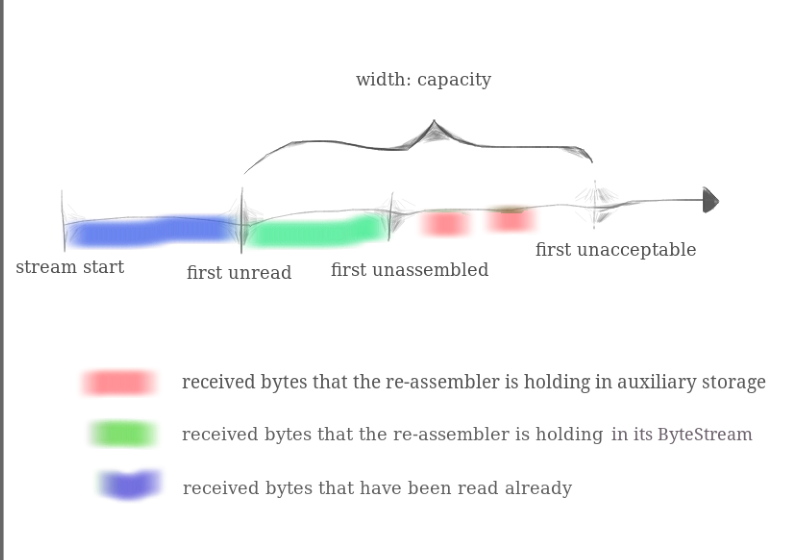
上图可以说是本次 Lab 的核心思路图了,只要把这图的逻辑理清就差不多做得出来了。蓝色部分是已经被用户进程读出的字节流,绿色和红色部分是 StreamReassembler 的内容,其中绿色部分表示已经整流完成写入 ByteStream 等待读取的字节流,红色部分表示读入 StreamReassembler 等待处理写入 ByteStream 的字节碎片,一旦接收的字节碎片超过 capacity 容量,后续到达的字节碎片将会被直接丢弃
整体思路
对于存储字节碎片的数据结构,这位老哥 使用了 std::set 和自建的 node 结构体来存乱序到来的字节碎片,重载了运算符使其自带对索引的排序效果。不过考虑到和 Lab0 实现的 ByteStream 相协调,我最后还是使用了双向队列 std::deque来存,下标对应索引顺序。实现起来也比他的简单一些
std::deque < char > _buffer ; //存储字节
std::deque < bool > _flag ; //记录该处是否存有字节
为什么要用两个队列来存呢?主要是考虑到空字符的影响。_buffer[i] = '\0 时有可能是空的,也有可能是对方传来的一个空字符,所以这时候就需要一个同步 flag 队列来辅助判断
然后就是考虑索引在范围之外的问题,如下图
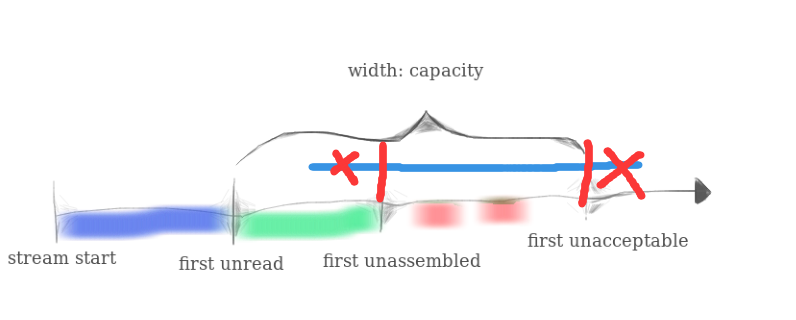 我们需要把在 first unassembled 和 first unacceptable 之外的部分(如果存在)裁剪掉
我们需要把在 first unassembled 和 first unacceptable 之外的部分(如果存在)裁剪掉
经过裁剪后的字节碎片就可以写入 _buffer 队列中了
存入队列中的字节流已经是有序的了,所以当队列的头部非空时,就可以执行操作将队列中从头部开始连续的字节流写入 ByteStream 中
完整代码如下:
stream_reassembler.hh
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
std::deque < char > _buffer ;
std::deque < bool > _flag ;
bool _first_in = true;
bool _is_eof = false;
size_t _eof_index = 0;
size_t _unassembled_bytes = 0;
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
public:
StreamReassembler(const size_t capacity);
void push_substring(const std::string &data, const uint64_t index, const bool eof);
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
size_t unassembled_bytes() const;
bool empty() const;
};
stream_reassembler.cc
#include "stream_reassembler.hh"
#include <iostream>
// Dummy implementation of a stream reassembler.
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by `make check_lab1`.
// You will need to add private members to the class declaration in `stream_reassembler.hh`
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity) :
_buffer(capacity,'\0') ,
_flag(capacity,false),
_output(capacity),
_capacity(capacity){}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
//size_t _first_unread = _start_index + _output.bytes_read();
size_t _first_unassembled = _output.bytes_written();
size_t _first_unaccept = _first_unassembled + _capacity;
//超出待读取范围的直接扔掉
if(index >= _first_unaccept || index + data.length() < _first_unassembled){ return ;}
//裁剪字符串开始和结尾的index
size_t begin_index = index;
size_t end_index = index + data.length();
if(begin_index < _first_unassembled){ begin_index = _first_unassembled;}
if(end_index >= _first_unaccept){ end_index = _first_unaccept;}
//元素入队
for(size_t i = begin_index;i < end_index;i++){
if(!_flag[i - _first_unassembled]){
_buffer[i - _first_unassembled] = data[i - index];
_unassembled_bytes ++;
_flag[i - _first_unassembled] = true;
}
}
string wait_str = "";
while(_flag.front() ){
wait_str += _buffer.front();
_buffer.pop_front();
_flag.pop_front();
//为了保持队列容量不变需要在后面添加空元素占位
_buffer.emplace_back('\0');
_flag.emplace_back(false);
}
if(wait_str.length() > 0){
stream_out().write(wait_str);
_unassembled_bytes -= wait_str.length();
}
if(eof){
_is_eof = true;
_eof_index = end_index;
}
if(_is_eof && _eof_index == _output.bytes_written()){
_output.end_input();
}
}
size_t StreamReassembler::unassembled_bytes() const { return _unassembled_bytes; }
bool StreamReassembler::empty() const { return unassembled_bytes() == 0; }
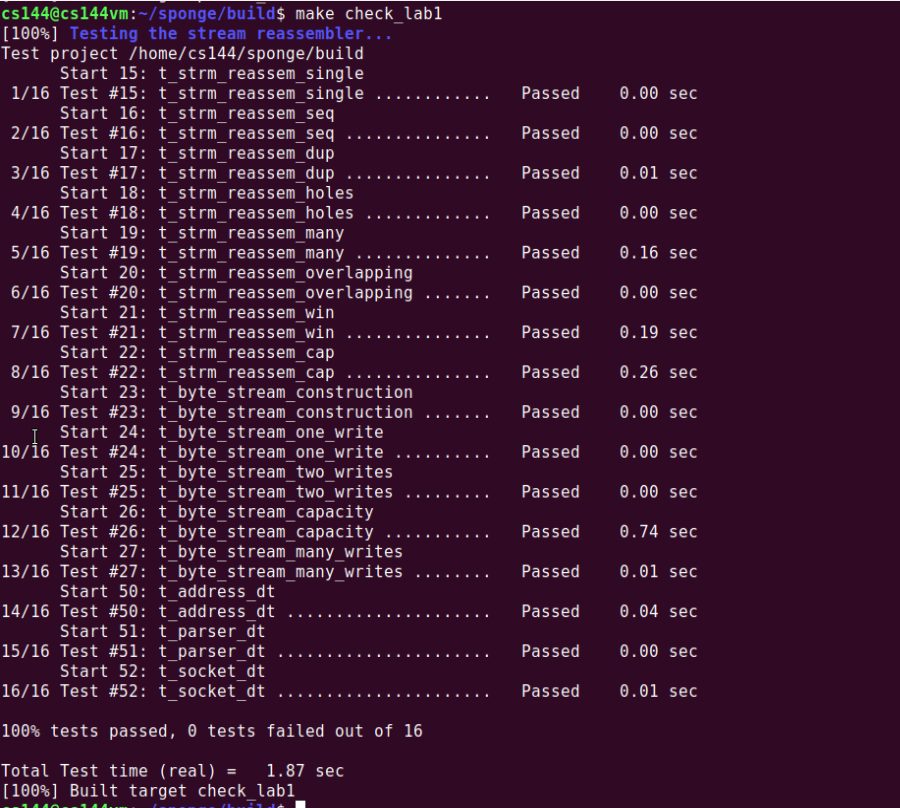
小结
虽然这次的任务看上去不多,看上去也好像很简单的样子。不过要理清思路还是挺费功夫和时间的。一开始我就是没理解好题目的意思急急忙忙就开始写,搞到一半发现跟题目要求的好像完全不一样。。。白白浪费了大半天时间。然后在测试过程中也是发现了几处小坑,记录一下
- 一开始我以为起始的 index 有可能不会从 0 开始,所以增设了一个 _start_index 变量来存
if(_first_in){
_start_index = index;
_first_in = false;
}
后来发现好像不太对劲,第一个到达的也不一定会是最前面的那个字节流啊。。把他删了之后测试就能过了,不过我有点奇怪,起始的索引一定是从 0 开始的吗?
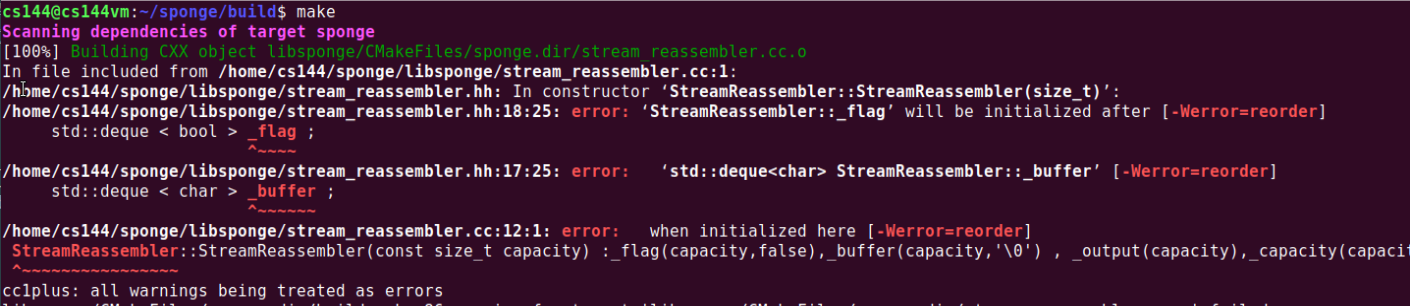
- 在构造函数初始化的时候没有按照在类中声明的顺序来初始化,报了一个 reorder 错误。语法问题了属于是,以前也从来没有注意过(也有可能是忘了2333)